$ARCHIVE¶
In order to simplify the storage mount points and the user experience in storing their data on the
Jubail HPC, We have merged the functionalities of two storages, $WORK (/work/<NetID>) and
$ARCHIVE (/archive/NetID>) into a single storage $ARCHIVE (/archive/<NetID>).
$ARCHIVE can be accessed on login nodes as follows:
cd $ARCHIVE
# is equivalent to
cd /archive/<your-NetID>
Caution
The /work/<NetID> has been discontinued from 2nd Feb 2023. The previous data in /work/<NetID> is
moved to /archive/work/<NetID> as a temporary staging area to allow users to move out their
existing data from $WORK to archive (/archive/<NetID>/…). The /archive/work/<NetID> is
available for the users from the 3rd of Feb 2023 and would be deprecated after a period of 180 days.
When storage is shared among many users, rules must be set to prevent users from consuming disk space
excessively at the expense of others. For this purpose, HPC systems enforce disk quotas to users and
groups of users. The regular cleanup of the /scratch/<NetID> storage is essential to maintain its efficiency
and easily manage the capacity.
Warning
The current policy is to remove any files(data) that have not been accessed (viewed, created or modified) for more than 90 days.
On the HPC, disk quotas are enforced on /home and /scratch (not /archive ).
- There are two quota constraints:
The total amount of disk space
The total number of files.
Once you reach a quota limit your jobs may be killed. So it is a good practice to check your quota before submitting a job that will generate a lot of data.
We urge our users to clean up their $SCRATCH storage regularly.
Run myquota command in the terminal on the HPC to check your current usage and quota.
Example output:
DISK SPACE # FILES (1000's)
filesystem size quota number quota
-------------------------- --------------------------
/home 131KB 20GB ( 0%) 0 100 ( 0%)
/scratch 220GB 5242GB ( 4%) 4 500 ( 1%)
/archive 418GB 5242GB ( 8%) 3 125 ( 3%)
What’s inside $ARCHIVE¶
The archive processes are described below in the form of a flowchart.

The
archivecomprises of two types of storages:Normal Storage (fast)
Long Term Storage - Tape drive (slow)
Process 1 : The data in the Tape drive is synced with the storage every 12 hours, so that a copy of the files is available on the Tape drive as well.
Process 2 : Once the usage of the total storage hits 80% , the system automatically frees up space by keeping only a copy of the file on the tape drive (which can be retrieved later).
The freeing up of space is in accordance with the access timestamp of the files which are oldest.
State of the file in $ARCHIVE¶
Since the $ARCHIVE acts both as a storage soultion and long term storage (tape drive) as well, hence the state
of the file plays an important role in the same. There are essentially two types of states for a file in
/archive.
archived state: The file has a copy on the storage and the tape drive as well.In the above figure,
file1,file2,file3,file4,file5are in thearchived stateas they are both available on the storage and the tape drive.released archived state: The file is only available on the tape drive and has been moved (released) from the storage to free up space.In the above figure,
file6,file7,file8,file9,file10are in thereleased archivedstate as they have been released/moved from the storage to the tape drive.
How to identify the state of a file¶
In order to identify the state of files in a directory:
#dmfls -d <path to archive directory>
#for example:
dmfls -d /archive/wz22/abc
In order to identify the state of a single file:
#dmfls <path to archive file>
#for example:
dmfls /archive/wz22/abc/input.txt
A sample output of the above directory command is shown below
[wz22@login4 ~]$ dmfls -d /archive/wz22/abc
./hwloc/gnu/build.txt: exists archived,
./hwloc/src/hwloc-1.7.1.tar.bz2: exists archived,
./blat/src/bedGraphToBigWig: exists archived,
./blat/src/liftOver: released exists archived,
./blat/src/blat: exists archived,
./cufflinks/src/cufflinks-2.0.2.Linux_x86_64.tar.gz: released exists archived,
./cufflinks/src/cufflinks-2.1.1.Linux_x86_64.tar.gz: released exists archived,
./crystal-analysis/gnu/crystal_analysis-0.9.12.tbz2: exists archived,
It can be seen above in the sample output that the state of a few files is released archived state while
some are in the archived state.
How to Archive and De Archive¶
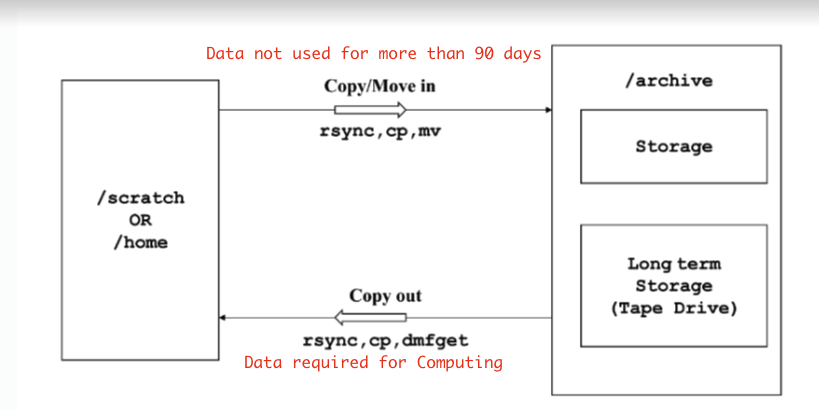
The above figure shows the following:
The data from
/scratchor/homecan be moved/copied to/archiveusing the usual unix commands (rsync,cp,mv)The commands to copy out data from
/archivedepend on the state of the file.
archived state
Since the
archived staterefers to the copy of the file available on both the storages, usual unix commands (cp , rsync) can be used to copy out the files from/archiveto your/scratch.
released archived state
Since the
released archived staterefers that the file has been moved/released and is now only available on the tape library, dearchiving the file would be a two-step process.It would have to be first moved from the tape to the normal storage using the
dmfget <filename>command and then can be copied out to the required directory in your/scratchusing the usual unix commands (rsync , cp).
A simple dearchiving would have the following steps:
Go to the required
/archivedirectory which you would like to copy out to your/scratch.
(base) [wz22@login1 ~]$ cd /archive/wz22/abc
Check the state of the file using the
dmfls <filename>command.
(base) [wz22@login1 abc]$ ls xyz.txt file2.txt (base) [wz22@login1 lib64]$ dmfls * xyz.txt: exists archived, file2.txt: released exists archived,
(optional) if there are files in the
released archived state, use thedmfget <filename>command to copy out them from the tape library to the storage to make them in thearchived state. This will run in the background and the progress can be tracked using thedmfmonitorcommand.(base) [wz22@login1 abc]$ dmfget * Execute watch dmfmonitor <directory/file_name> to see progress (base) [wz22@login1 abc]$ dmfmonitor * xyz.txt: NOOP file2.txt: RESTORE running (0 bytes moved) (base) [wz22@login1 abc]$ dmfmonitor * xyz.txt: NOOP file2.txt: NOOP (base) [wz22@login1 lib64]$ dmfls * xyz.txt: exists archived, file2.txt: exists archived,
Note that in the command
dmfmonitorwhen the status corresponding to the file isNOOP, means that the file is now back in the storage and in thearchivedstate.Copy out the file from
/archiveto desired location in/scratchusing the usual unix commands (cp , rsync).
(base) [wz22@login1 abc]$ cp -r /archive/wz22/abc /scratch/wz22/.
Tip
A user can simply use the standard unix utilities like rsync, cp etc. to copy in or out the data
from/to /archive. While copying out from archive, the rest of the dmfget command would be automatically handled in the background and
hence the time taken for the moving out would depend on the state of the file (released/exists).
Any operation performed on the archive files would first auto transfer the file to the exists archived state before
performing the operation.
Quick Glance into the archive commands¶
Action |
Command |
Remarks |
|---|---|---|
Navigating to archive |
|
usual unix commands ( |
List the state of the files |
|
check for |
Retrieve from Tape drive to Storage |
|
use when the file is in the |
Monitor the state of a file |
|
Can be used to track if the migration from tape drive to storage is done. |
Summary¶
Action |
Command |
Remarks |
|---|---|---|
Copy in to Archive |
rsync <source-dir> <dest-dir>
|
Usual commands like rsync and cp can be used to copy in to |
Copy out from archive |
rsync <source-dir> <dest-dir>
|
Usual commands like rsync and cp can be used to copy out from |
Best Practices¶
Dos |
Remarks |
|---|---|
Periodically clean your |
Files which have not been access for 90 days in |
Once a project is completed move the data over to |
Moving data to |
Use tar files to archive directories with large file count |
Lesser the number of files, faster is the archiving and dearchiving process |
Note
$ARCHIVE can also be mounted on your workstation, Linux,Mac and Windows.
Instructions are in this page: Mount $ARCHIVE with SSHFS